I. The Document Object Model (DOM)
Document object—which represents the HTML document that is displayed in a browser window or tab.
HTML documents contain HTML elements nested within one another, forming a tree.
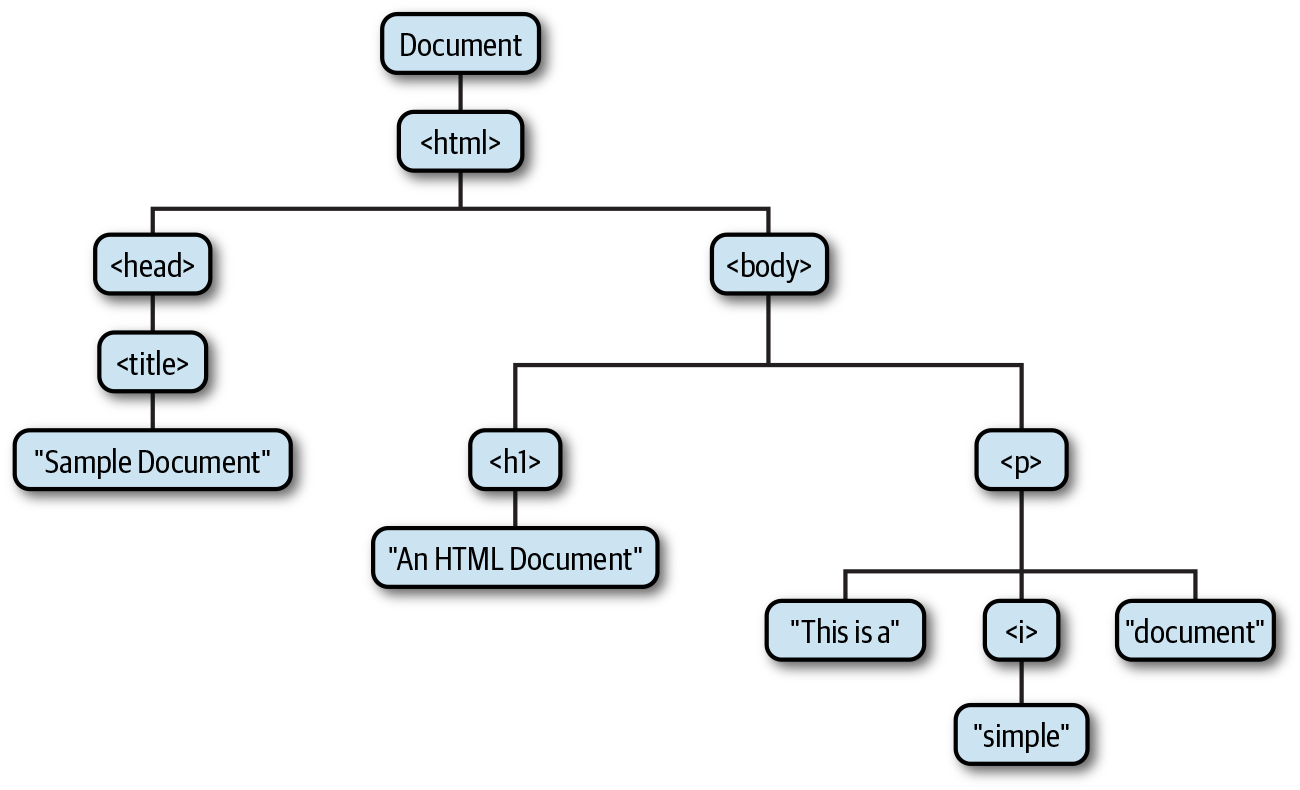 Sample Document
Sample Document
The DOM API mirrors the tree structure of an HTML document. For each HTML
tag in the document, there is a corresponding JavaScript Element object, and for each
run of text in the document, there is a corresponding Text object. The Element and Text classes, as well as
the Document class itself, are all subclasses of the more general
Node class, and Node objects are organized into a tree structure that JavaScript can
query and traverse using the DOM API.
Selecting Document Elements
The global document property refers to the Document object,
and the Document object has head and body properties that refer to the Element
objects for the <head> and <body> tags, respectively.
let My_DIV = document.getElementById("DIV_ID");
let My_Input = document.getElementsByName("Input_Name");
let The_H1 = document.getElementsByTagName("h1");
let Btn = document.getElementsByClassName("Btn_Class");
These selection methods that are more or less obsolete now.
Selecting elements with CSS selectors
The DOM methods querySelector() and querySelectorAll() allow us to find the element or elements within a
document that match a specified CSS selector.
The querySelector() method takes a CSS selector string as its argument and returns the first matching element
in the document that it finds, or returns null if none match.
querySelectorAll() is similar, but it returns all matching elements in the document rather than just returning
the first.
The return value of querySelectorAll() is not an array of Element objects. Instead,
it is an array-like object known as a NodeList. NodeList objects have a length property
and can be indexed like arrays.
If you want to convert a NodeList into a true array, simply pass it to Array.from().
The NodeList returned by querySelectorAll() will have a length property set to 0 if
there are not any elements in the document that match the specified selector.
querySelector() and querySelectorAll() will only return elements that are descendants of that element.
document.getElementById("DIV_ID");= document.querySelector("#DIV_ID")
document.getElementsByName("Input_Name");
=document.querySelectorAll('*[name="Input_Name"]');
document.getElementsByTagName("h1");=document.querySelectorAll("h1")
document.getElementsByClassName("Btn_Class");
=document.querySelectorAll(".Btn_Class")
Unlike querySelectorAll(), however, the NodeLists returned by these older selection methods
are “live,”
which means that the length and content of the list can change if the document content or structure changes.
Document Structure and Traversal
Once you have selected an Element from a Document, you sometimes need to find
structurally related portions (parent, siblings, children) of the document.
there is a traversal API
that allows us to treat a document as a tree of Element objects, ignoring Text nodes
that are also part of the document. This traversal API does not involve any methods;
it is simply a set of properties on Element objects that allow us to refer to the parent,
children, and siblings of a given element.
- parentNode: This property of an element refers to the parent of the element, which will be another Element or a Document object.
- children: This NodeList contains the Element children of an element, but excludes non- Element children like Text nodes (and Comment nodes).
- childElementCount: The number of Element children. Returns the same value as children.length.
- firstElementChild, lastElementChild: These properties refer to the first and last Element children of an Element. They are null if the Element has no Element children.
- nextElementSibling, previousElementSibling: These properties refer to the sibling Elements immediately before or immediately after an Element, or null if there is no such sibling.
document.firstElementChild.firstElementChild.nextElementSibling
Documents as trees of nodes
If you want to traverse a document or some portion of a document and do not want
to ignore the Text nodes, you can use a different set of properties defined on all Node
objects. This will allow you to see Elements, Text nodes, and even Comment nodes.
- parentNode: The node that is the parent of this one, or null for nodes like the Document object that have no parent.
- childNodes: A read-only NodeList that that contains all children (not just Element children) of the node.
- firstChild, lastChild: The first and last child nodes of a node, or null if the node has no children.
- nextSibling, previousSibling: The next and previous sibling nodes of a node. These properties connect nodes in a doubly linked list.
- nodeType: A number that specifies what kind of node this is. Document nodes have value 9. Element nodes have value 1. Text nodes have value 3. Comment nodes have value 8.
- nodeValue: The textual content of a Text or Comment node.
- nodeName: The HTML tag name of an Element, converted to uppercase.
document.firstChild.firstChild.nextSibling
Then the second child of the first child is the <body> element. It has a nodeType of 1 and a nodeName of “BODY”.
Attributes
HTML elements consist of a tag name and a set of name/value pairs known as
attributes.
The Element class defines general getAttribute(), setAttribute(), hasAttri
bute(), and removeAttribute() methods for querying, setting, testing, and removing
the attributes of an element. But the attribute values of HTML elements are available as properties of the
HTMLElement objects that represent those elements.
HTML attributes as element properties
HTML attributes are not case sensitive, but JavaScript property names are.
For some elements, such as the <input> element, some HTML attribute names map
to differently named properties. The HTML value attribute of an <input>, for example,
is mirrored by the JavaScript defaultValue property. The JavaScript value property
of the <input> element contains the user's current input.
Some HTML attribute names are reserved words in JavaScript. For these, the general
rule is to prefix the property name with “html”. The HTML for attribute (of the
<label> element), for example, becomes the JavaScript htmlFor property. “class” is a
reserved word in JavaScript, and the very important HTML class attribute is an
exception to the rule: it becomes className in JavaScript code.
The class attribute
The class attribute of an HTML element is a particularly important one. Its value is a
space-separated list of CSS classes that apply to the element and affect how it is styled
with CSS.
Because class is a reserved word in JavaScript, the value of this attribute is
available through the className property on Element objects. The className property
can set and return the value of the class attribute as a string. But the class attribute is poorly named: its
value is a list of CSS classes, not a single class.
Element objects define a classList property that allows you to treat
the class attribute as a list (add(), remove(), and contains() methods).
Dataset attributes
In HTML, any attribute whose name is lowercase and begins with the prefix
“data-” is considered valid, and you can use them for any purpose. These “dataset
attributes” will not affect the presentation of the elements on which they appear, and
they define a standard way to attach additional data without compromising document
validity.
In the DOM, Element objects have a dataset property that refers to an object that
has properties that correspond to the data- attributes with their prefix removed.
Thus, dataset.x would hold the value of the data-x attribute. Hyphenated attributes
map to camelCase property names: the attribute data-section-number becomes the
property dataset.sectionNumber.
Element Content
Element content as HTML
Reading the innerHTML property of an Element returns the content of that element as
a string of markup. Setting this property on an element invokes the web browser's
parser and replaces the element's current content with a parsed representation of the
new string.
The outerHTML property of an Element is like innerHTML except that its value
includes the element itself. When you query outerHTML, the value includes the opening
and closing tags of the element. And when you set outerHTML on an element, the
new content replaces the element itself.
A related Element method is insertAdjacentHTML(), which allows you to insert a
string of arbitrary HTML markup “adjacent” to the specified element. The markup is
passed as the second argument to this method, and the precise meaning of “adjacent”
depends on the value of the first argument. This first argument should be a string
with one of the values “beforebegin,” “afterbegin,” “beforeend,” or “afterend.”

Element content as plain text
To query the content of an element as plain text or to insert plain
text into a document use the textContent property.
The textContent property is defined by the Node class, so it works for Text nodes as
well as Element nodes. For Element nodes, it finds and returns all text in all descendants
of the element.
Creating, Inserting, and Deleting Nodes
Create a new element with the createElement() method of the Document class and
append strings of text or other elements to it with its append() and prepend()
methods.
append() and prepend() take any number of arguments, which can be Node objects
or strings. String arguments are automatically converted to Text nodes.
append() adds the arguments to the element at the end of the child
list. prepend() adds the arguments at the start of the child list.
If you want to insert an Element or Text node into the middle of the containing element's
child list, you should obtain a reference to a sibling node and call before() to insert the new
content before that sibling or after() to insert it after that sibling.
Like append() and prepend(), after() and before() take any number of string and
element arguments and insert them all into the document after converting strings to
Text nodes. append() and prepend() are only defined on Element objects, but
after() and before() work on both Element and Text nodes.
Note that elements can only be inserted at one spot in the document. If an element is
already in the document and you insert it somewhere else, it will be moved to the new
location, not copied.
If you do want to make a copy of an element, use the cloneNode() method, passing
true to copy all of its content:
Parent_Div.after(DIV.cloneNode(true));
You can remove an Element or Text node from the document by calling its remove()
method, or you can replace it by calling replaceWith() instead. remove() takes no
arguments, and replaceWith() takes any number of strings and elements just like
before() and after() do.
CSS Classes
The simplest way to use JavaScript to affect the styling of document content is to add
and remove CSS class names from the class attribute of HTML tags. This is easy to
do with the classList property of Element objects.
Inline Styles
The DOM defines a style property on all
Element objects that correspond to the style attribute. Unlike most such properties,
however, the style property is not a string. Instead, it is a CSSStyleDeclaration
object.
When working with the style properties of the CSSStyleDeclaration object, remember
that all values must be specified as strings.
Naming Conventions: CSS Properties in JavaScript
Many CSS style properties, such as font-size, contain hyphens in their names. In
JavaScript, a hyphen is interpreted as a minus sign and is not allowed in property
names or other identifiers.
If a CSS property name contains one or more hyphens, the CSSStyleDeclaration property
name is formed by removing the hyphens and capitalizing the letter immediately following
each hyphen. For example, and the CSS font-family property
is written as fontFamily in JavaScript.